ElegantRL小雅:基于PyTorch的深度强化学习框架

近年来,不少研究者和机构都在研究使用深度强化学习技术解决量化交易问题,其中FinRL 是在这一领域中展示了巨大的潜力的 Python 开源项目。FinRL最初由哥伦比亚大学的一个研究团队提出,是适用于量化交易的深度强化学习项目,为从业人员提供用于流程化策略开发的统一项目模板。FinRL目前由开源社区 AI4Finance 进行维护,他们提供了量化金融中深度强化学习(DRL)的教育资源,对学习者非常友好。
1.项目概述
FinRL项目主要是为了解决跨市场交易、动态交易价格和以动态交易数量等相关交易决策问题,项目包含FInRL、ElegantRL(小雅)、FinRL-Meta,分别解决策略层、算法层和应用层的问题。
- FinRL:流程化生成和管理交易策略
- ElegantRL(小雅):开发和优化深度强化学习算法,提供了轻量级的DRL算法库,其中包含DDPG,TD3, SAC, PPO(GAE),DQN,DoubleDQN, DuelingDQN, D3QN,并支持用户自定义算法
- FinRL-Meta:通过FinRL-Meta对接不同交易市场
AI4Finance 团队认为评价DRL库的指标应当包括ReplayBuffer、RL训练数据的吞吐、算法依赖关系、是否区分on-policy和off-policy、多进程的控制中心等。此前在强化学习社区中流行的DRL开源库包括伯克利的RLlib ray,OpenAI的baselines,hill的stable baselines,stable baselines 3,莫烦的教学代码,来自清华大学团队的“天授”等。FinRL作为新晋的DRL项目,吸取社区中的项目的优势,也进化出更多的新特性。
基于这样的认知,AI4Finance 主张创立更好上手、更容易使用的DRL,团队将其理念植入ElegantRL的中文名“小雅”的名字中。
“小”:只需安装 PyTorch 和 Matplotlib 用于网络训练以及画图协助调参,整个库只有4个 py 文件,并且tutorial版将一直维持在1000行代码以内,保持与最新版使用相同的变算法库量名与代码结构,把学习成本降到最低。
“雅”:代码优雅,可读性高,耦合度低,可移植性高。ElegantRL具备DRL算法的基本模板,都继承自一个基类。只要照着模板编写新算法,就能自动支持多进程训练。
高性能:ElegantRL在支持多进程训练后,最新版最要支持多GPU训练了。RL与DL的不同导致它的分布式不能照搬DL的多GPU训练模式,所以无法直接使用PyTorch 或TensorFlow 这些深度学习框架自带的多GPU训练模块。
以下内容由Luke翻译自 ElegantRL: a lightweight and stable deep reinforcement learning library 内容有部分改动
2.ElegantRL的特点
ElegantRL能够帮助研究人员和从业者更便捷地“设计、开发和部署”深度强化学习技术。ElegantRL的 elegant 体现在以下几个方面:
轻量:代码量低于1000行
高效:性能向Ray RLlib靠拢
稳定:ElegantRL支持离散动作空间以及连续动作空间下的常用DRL算法,并且提供了十分友好的教程
3.总述:文件结构和函数
ElegantRL的“小”最直观的体现就是:整个库只有3个文件,net.py, agent.py, run.py。 再加上env.py 用于存放与训练环境有关的代码。在Tutorial版用小于1000行的代码对一个完整的DRL库进行实现,这对想要入门深度强化学习的研究者有莫大的帮助。
Tutorial版的ElegantRL适用于以学习为目的的研究者,如果想要把ElegantRL当成生产工具,研究者就需要使用最新版的ElegantRL,其文件结构和函数保持了与 Tutorial版的统一。
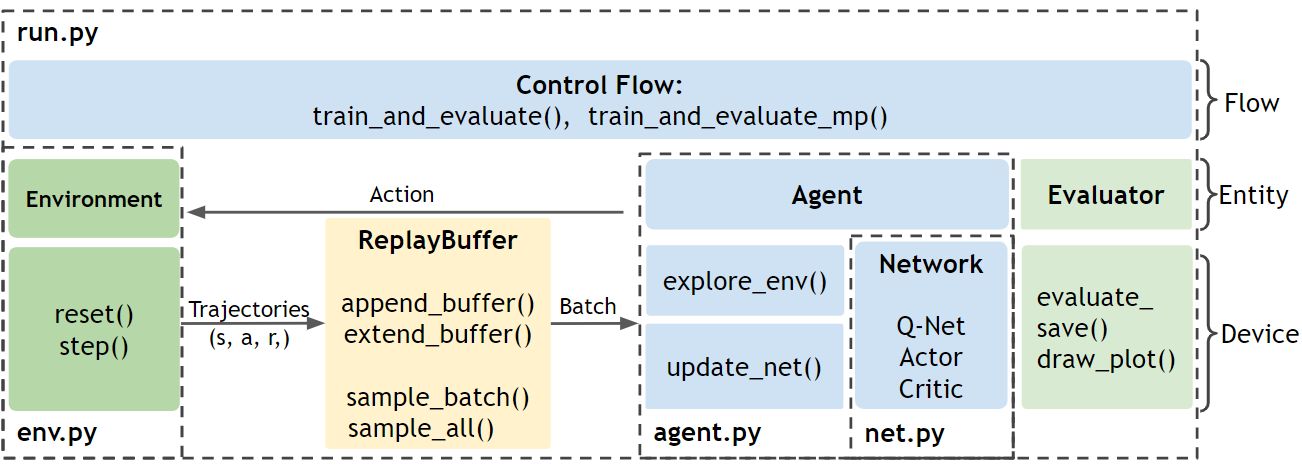
图1: Agent.py中的Agent使用Net.py中的网络,在Run.py中通过与Env.py中的环境互动来训练
ElegantRL的文件结构如图1所示:
Env.py:包含与Agent互动的环境
· PreprocessEnv类,可用于对gym的环境进行改动
· 包括自主开发的股票交易环境作为用户自定义环境的例子
Net.py:包含三种类型的网络,每个类型均包括一个网络基类,以便于针对不同算法进行继承与派生
· Q网络
· Actor网络
· Critic网络
Agent.py:包含不同用于算法的Agent
Run.py:提供用于训练和测试的基本函数
· 参数初始化
· 训练
· 评测
从一个较高的层面描述这些文件之间的关系:首先,初始化Env.py文件中的环境和Agent.py文件中的Agent。Agent 既有包含在Net.py 文件中的网络,又与Env.py 文件中的环境进行互动。在Run.py 中进行的每一步训练中,Agent都会与环境进行互动,产生transitions 并将其存入回放缓存(Replay Buffer)。之后,Agent从Replay Buffer 中获取数据来更新它的网络。每一步更新后,都会有一个评测器来评测并保存表现好的Agent。
4.网络类的集合 net.py
net.py 文件存放了算法库会使用到的神经网络,共分为了三类:
'''Q 网络'''
class QNet(nn.Module):
class QNetDuel(nn.Module):
class QNetTwin(nn.Module):
class QNetTwinDuel(nn.Module):
'''Policy 网络(Actor)'''
class Actor(nn.Module):
class ActorPPO(nn.Module):
class ActorSAC(nn.Module):
'''Value 网络(Critic)'''
class Critic(nn.Module):
class CriticAdv(nn.Module):
class CriticTwin(nn.Module):这为使用者微调算法提供了极大的便利。例如:把图片作为state输入神经网络时,只需要到 net.py 将全连接层修改为卷积层即可。这种模式把深度神经网络与强化学习隔开,提高了代码的可读性。debug的时候,把net.py单独列出来,并把计算张量的计算加到网络里。类似的很多细节都是团队从2019年总结至今的成果。“小雅:ElegantRL”并没有很重的历史包袱,团队直到最近才将其发布,为的就是争取更多机会对整个架构进行调整。
5.DRL算法的构建 agent.py
agent.py存放了不同的DRL算法。在这一部分将分别描述DQN系列算法和DDPG系列算法。ElegantRL中每一个DRL算法的Agent都继承自它的基类。
DQN系列中的Agent类:
class AgentDQN:
class AgentDuelingDQN(AgentDQN):
class AgentDoubleDQN(AgentDQN):
class AgentD3QN(AgentDoubleDQN):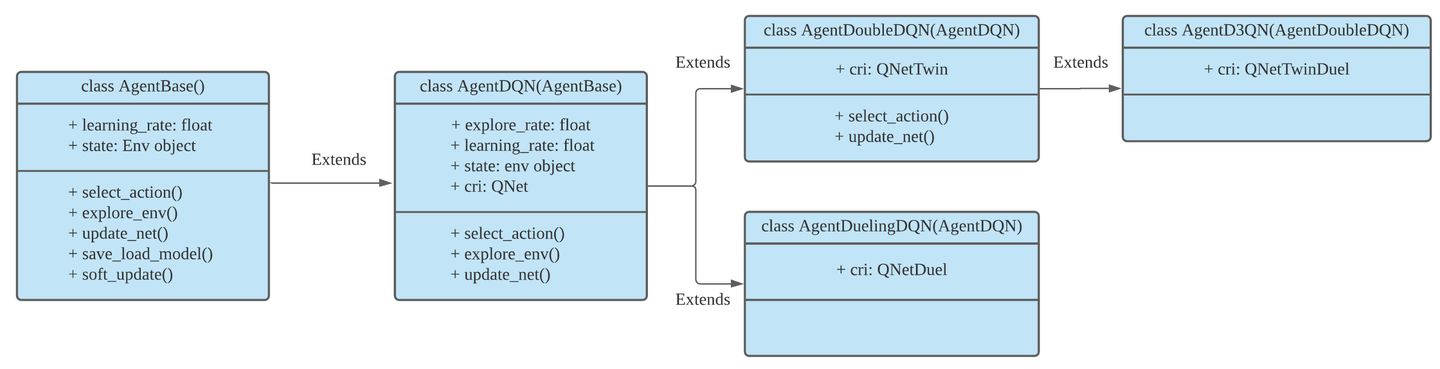
图2. DQN系列的继承层级关系
如图2所示,ElengtRL中DQN系列的继承层级关系为- AgentDQN:标准的DQN Agent
- AgentDoubleDQN:为了减少过高估计而包含两个Q网络的Double-DQN,继承自AgentDQN
- AgentDuelingDQN:采用不同的Q值计算方式的DQN Agent,继承自AgentDQN
- AgentD3QN:AgentDoubleDQN和AgentDuelingDQN的结合,继承自 AgentDoubleDQN
DDPG系列中的Agent类:
class AgentBase:
class AgentDDPG(AgentBase):
class AgentTD3(AgentDDPG):
class AgentSAC(AgentBase):
class AgentPPO(AgentBase):
class AgentModSAC(AgentSAC): # Modified
class AgentInterSAC(AgentBase): # InterXXX表示parameter sharing
class AgentInterPPO(AgentBase): # InterXXX表示parameter sharing
...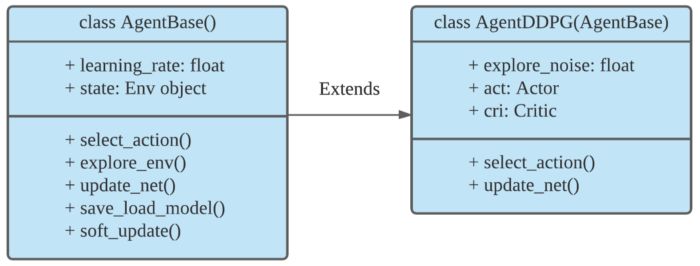
图 3. DDPG系列的继承层级关系
如图3所示,ElegantRL中DDPG系列的继承层级关系为
- AgentBase:所有A-C框架下Agent的基类,包括所有Agent共有的参数。
- AgentDDPG:DDPG Agent,继承自AgentBase。
- AgentTD3:采用新的更新方式的TD3 Agent,继承自AgentDDPG
在构建DRL算法的Agent时,采用的这种层级结构极大地提升了ElegantRL的轻量性和高效性。当然,用户也可以按照类似的方式构建自己的Agent。

图4. Agent的数据流
从根本上来说,每一个Agent都由两大基本功能构成。从数据流的角度可描述为图4的形式
- 探索环境 explore_env: Agent利用与环境互动,在此过程中产生用于训练网络的数据。
- 更新网络 update_net: Agent从回放缓存 Replay Buffer 中获取数据(一批transitions),并利用这些数据来更新网络。
经验回放缓存:
class ReplayBuffer:
class ReplayBufferMP:6.训练流程 run.py
训练一个DRL Agent包含两大步:
- 初始化:
args = Arguments(): 加载默认的超参数
env = PreprocessEnv():创建(gym)环境。
agent = agent.XXX:基于算法创建Agent。
evaluator = Evaluator():用于评测并保存模型。
buffer = ReplayBuffer():回放缓存。- 通过一个while循环来控制训练过程,这个while循环只有当达到某些特定条件时才会终止,比如获得目标分数,达到最大步数或人为终止:
agent.explore_env(...):
Agent在规定的步数内探索环境,产生transitions并将其保存至回放缓存(Replay Buffer)。
agent.update_net(...):
Agent根据回放缓存(Replay Buffer)中的一批数据来更新网络参数。
evaluator.evaluate_save(...):
评测Agent的表现,并保存具有最高得分的模型参数。 关于ElegantRL的Demo的更多信息,可以参考以下内容进行了解
ElegantRL Demo: Stock Trading Using DDPG PartI
ElegantRL Demo: Stock Trading Using DDPG PartII
矩池云支持FinRL镜像,通过“主机市场-租用-选择FinRL镜像”可直接运行框架