面向程序员的实用深度学习课程2022
Practical deep learning for coders 是fast.ai出品系列课程,深受学员欢迎,该课程的上一版本视频已经在线浏览超600万次。经过两年时间的打磨,该课程的最新版已经发布。课程主讲fast.ai创始人Jeremy Howard授课思路清晰,力求用更精简的代码,实现更高的运行效率、更好地演示解构及上手实践。该视频内容已经由矩池云进行翻译。
课程全套视频
2022版亮点:
- 更注重互动探索。学生将手动构建简单的GUI,用于构建决策树、线性分类器以及非线性模型,并利用这些经验深入直观地理解基础算法的工作原理。
- 使用了更多的库+服务,包括Huggingface生态系统(Transformers, Datasets, Spaces, 以及Model Hub)、Scikit Learn和Gradio等。
- 教学内容包含这两年新起的框架,如ConvNeXt、Visual Transformers (ViT)和DeBERTa v3 等。听完第二课,学生就能够根据自己的数据建立并部署深度学习模型。听过该课程的很多学生会“花式”发布他们的项目,比如一个恐龙分类器!
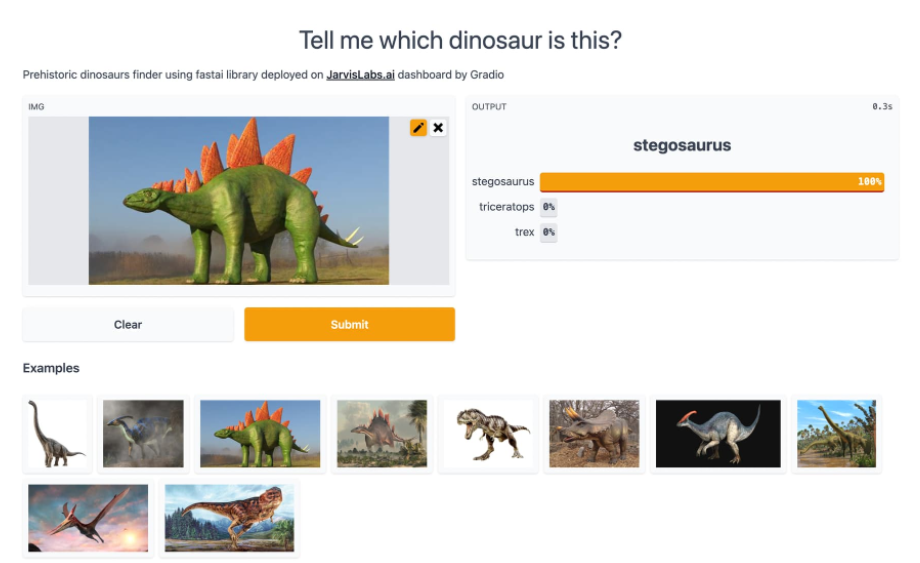
2022版课程涵盖的主题包括:
- 如何在计算机视觉、自然语言处理(NLP)、表格分析和协同过滤中创建并训练深度学习模型
- 创建随机森林和回归模型
- 如何将你的模型转化为实际的Web应用程序,并进行部署
- 如何使用PyTorch,以及fast.ai和Huggingface等
- 为什么以及如何使用深度学习模型,以及如何使用这些知识提高模型的准确率、速度和可靠性
- 最新的深度学习技术,及其实战技巧
- 如何实现深度学习算法从无到有,包括随机梯度下降以及完整的训练循环
课程内容
课程分为8节,每节课大约90分钟。课程内容主要基于《Deep Learning for Coders with fastai and PyTorch》一书(可免费在线阅读)。课程不需要你配备专门的硬件或软件,课程会告诉你如何使用免费资源来构建和部署模型;不需要你具备大学水平的数学能力(高中数学水平就够了),必要的微积分和线性代数课程包教包会;甚至不需要传说中的海量数据,只有50个数据样本就能达到SOTA。
第一课-入门准备
在本节前5分钟内,你就能看到训练一个模型的完整过程及其应用情况,而这在2015年看来是不可能实现的。在这门课中还将讨论什么是深度学习和神经网络,以及它们的用途,并且介绍了深度学习用于计算机视觉物体分类、图像分割、表格分析和协同过滤的例子。
第二课-部署
这节课展示了如何设计你自己的机器学习项目,创建你自己的数据集,用你的数据训练模型,最后在web上实现应用程序部署。我们使用Hugging Face Space和Gradio进行部署,同时使用JavaScript实现浏览器界面,部署到其他服务器的方法与本课中教授的方法非常相似,所以也可以作为基础。
第三课-神经网络基础
本节课主要讲的是深度学习的数学基础,如随机梯度下降(SGD),矩阵乘积,线性函数与非线性激活函数分层的灵活性,也将重点关注线性整流函数(ReLU函数)。
第四课-自然语言(NLP)
这节课的重点在于研究如何使用自然语言处理(NLP)分析自然语言文档。课程将介绍HuggingFace生态,尤其是Transfomers库,以及大量预训练过的NLP模型。课程随堂项目是对用于描述美国专利的短语的相似性进行分类,类似的方法可以应用于各种领域的各式实际问题,如营销、物流和医药。
第五课-模型从无到有
课程将介绍使用Python和PyTorch从零开始创建一个神经网络,以及如何实现训练循环来优化模型的权重。我们从单层的回归模型开始,创建有一个隐含层的神经网络,再在此基础上创建深度学习模型。在这个过程中,我们还将了解如何使用sigmoid的特殊函数来简化二进制分类模型的训练,并了解各种指标。
第六课-随机森林
随机森林在20年前的机器学习领域掀起了一场变革。随机森林这种快速可靠的算法的出现,使得它几乎不需要对数据的形式做任何假设,也几乎不需要任何预处理。本节课会带你了解随机森林的工作原理,以及如何从零开始构建一个随机森林。你还会同时了解到如何通过随机森林来更好地理解你的数据。
第七课-协同过滤和嵌入
我们几乎每天都要和推荐系统(recommendation systems)打交道。推荐系统是一种根据你过去的行为猜测你可能喜欢的产品和服务的算法,它在很大程度上依赖协同过滤(collaborative-filtering)。协同过滤是一种基于线性代数的方法,可以填补矩阵中缺失的值。在这节课中,我们会看到有两种方法可以实现:一种是基于经典线性代数公式,另一种是基于深度学习。在学习协同过滤之后我们会探讨嵌入(许多深度学习算法的关键构建块)。
第八课-卷积(CNNs)
在这一节中,我们会深入讲解卷积神经网络(CNNs),了解它的工作机制。在之前的课上,我们已经使用过大量的CNN,但并没有深究它的底层工作原理和机制,而这节课就将把这些知识补全。除了学习CNN最基本的构建模块——卷积,我们还会研究池化pooling、dropout等概念。
课程主讲
课程由fast.ai创始人Jeremy Howard亲授。Jeremy Howard在业界可谓大名鼎鼎。他是大数据竞赛平台 Kaggle 的前主席和首席科学家,还是 Kaggle 两届冠军选手。他是美国奇点大学(Singularity University)最年轻的教职工。曾于 2014 年,作为全球青年领袖,在达沃斯论坛上发表主题演讲。他在 TED 上的演讲 The wonderful and terrifying implications of computers that can learn 收获高达 200 万的点击。同时,他还创立了 Enlitic, FastMail,以及 Optimal Decisions Group 三家科技公司,并担任 CEO。2017 年他又创立了 fast.ai技术分享平台,免费提供关于深度学习技术的系列视频教程,以帮助从业者迅速开发人工智能相关产品。
