Python生态下用GPU进行数据科学计算加速的实践经验&案例

在Python相关数据科学领域的社区中,近年来有一个计算资源选择的趋势:在数据挖掘阶段,比如数据清洗、抽取和特征工程,开发者基本倾向使用 CPU ,调 CPU 下的一些包;进入建模阶段之后,尤其在深度学习任务中,开发者会用 GPU 来处理模型训练和推断。这两个阶段任务对应的包的底层物理计算架构,是切割得非常清楚的,当然一些开发者可能由于 GPU 资源不够用,会把建模和推理部分也放在 CPU 里处理,但是很少看到有人会把比如ETL、因子抽取等这些工作放在 GPU 中处理。
之所以出现这种情况,主要是由于异构计算对资源要求比较高。原先这些计算资源没有补齐,但是就目前来说,开发者已经比较容易获得 GPU 资源或者其他一些计算资源。我今天想和大家分享的是因子抽取、ETL 等这些工作在 GPU 的支撑下会体现出更好的性能,接下来我会围绕一个具体的作业案例跟大家进行分享。
import pandas as pd
import numpy as np
from time import time, perf_counter, sleep
np.random.seed(42)
M = 50000
N = 50000
A = pd.DataFrame(np.random.random((M, N))).astype('float32')
B = pd.DataFrame(np.random.random((M, N))).astype('float32')
print('Data loading completed!')
sleep(15)
print('Computation begins!')
start=time()
result = A.rolling(20).corr(B)
end=time()
result = result[~result.isnull().any(axis=1)]
result = result.reset_index()
result = result.drop('index', 1)wo
print (result.tail())
print ('running time is %s Seconds' % (end-start))以上的作业案例比较简单,大体内容是有两个五5万乘以5万的矩阵,我们希望通过移窗求相关性系数。稍微有一些大数据经验的朋友都知道,5万乘以5万的数据量是一个很小的数量级。这段代码本身很简单,用的包也很简单——Pandas 的 Numpy,应该说是 Python 生态下面做数据科学计算最常用的一个包。我同时简单介绍一下这次计算的物理环境:有一个 20 个核心的 CPU,64G 的内存,还有一块3090的显卡,24G 显存。我们现在就准备拿刚才那一份脚本来跑。大家可以想一下,刚才那个小脚本在这样的环境下面跑,会出现什么样的问题?
脚本跑起来之后,大家会发现内存的占用增加地非常快。我们设置为在数据加载完成和计算开始的时候都会做打印,在数据加载的阶段,内存占用情况比较危险,数据加载完成后,内存已经用掉大约 20G 了。从常规经验来说,这个占用情况是比较出乎意料的,因为这只是两个 5 万乘 5 万的矩阵,而且我们进行的是单精度计算。这个任务失败原因是内存不足。我们用一个常规 Pandas 的 Numpy 的处理包,在这样的物理资源之下居然跑不了一个相对简单的任务。现在我们把矩阵排成 5 万乘 1 万再看一下具体的耗时情况。这个任务在改写后,可以执行完成,其用时是 45 秒。我们稍后会尝试把刚才的任务在 GPU 环境下运行,会用到一些 GPU 的上的包,我们将对其进行改写和迁移,再看性能上会不会有较大的提升。
Python的GPU计算生态
在数据科学的领域里面,GPU 相较于 CPU,其性能优势体现在哪里?首先最显著的是特点是 GPU 为多核,一般有上千核心,但是 GPU 的单核心和 CPU 处理器的单核心在性能上相比是差了很多的。待执行的任务如果是一个能非常好地进行并行化的结构表,并且每一个计算单位的计算复杂度不是特别高,我们可以通过并行化对其进行计算。这种情况下,如果我们把任务分配给 GPU 去计算的话,一般都会获得很大的效率提升。
Python 生态下面有很多 GPU 计算相关的包,尤其是刚刚过去的这三四年里,社区里很多项目都开始做数据科学相关的类,比如说 Pandas 或者 Numpy。当然大家最熟悉还是 Tensorflow、Pytorch 这些面向 AI 的 Python上层的包。
· CUDA API:Numba,CuPy,PyCUDA
· 类Pandas:cuDF,Dask-cuDF
· 类SciKit-learn:cuML
· 类NumPy:cuNumeric
· 类NetWorkX:cuGraph
· 上层框架:TensorFlow,Pytorch等
我梳理了一些包,这里也有我用过一些,比如 cuDF。从使用上面来说,现在还有很多比较基础的计算子没有被覆盖,在实际使用当中也会有一些未知的 bug。当然,一个软件包在它的发展初期,很容易出现类似的问题。总体使用下来,我感到 Numba 在发展了十几年之后,在 GPU 的作业任务里使用起来是比较稳定的。另外 Numba 是直接用 Python 去封装 CUDA 的,大家使用起来也会比较顺手。因为 Numba 是直接调 CUDA 层,所以计算的适应性、覆盖性都比较高。在稍后的案例中,我也会用 Numba 来运行。在具体进行 GPU 编程之前,我会简单介绍 GPU 编程、异构计算的基本概念。
GPU编程硬件基础
CPU 和储存设备(也就是我们常说的内存),一般统称为主机 Host;GPU 和显存的部分称为设备,主机和设备之间在主板上通过 bus 进行通信。也就是说,我们的数据先通过 CPU 的一些包把先拉取到内存里,但如果要放到 GPU 上去计算,是要先把这个数据迁移到 GPU 的显存里面才能够进行计算。计算完成后,如果计算最终需要在 CPU 的里面和 CPU 下面的内存里面做计算验证,那么还是要把数据通过总线(bus)从显存里面迁移出去。我们谈到性能调优,是主要是围绕 bus 层进行通信资源和计算资源的调用和优化。

· 核函数:表示该函数是一个在GPU设备上运行的函数,需要在核函数上添加@cuda.jit装饰符。
· 执行配置:主函数调用GPU核函数时,需要添加如[2, 4]这样的执行配置,例如gpu_print2, 4表示同时开启8个线程并行地执行gpu_print函数,函数将被并行地执行8次。
· 计算同步:由于CPU与GPU在任务执行上是异步的,如果CPU任务需要GPU的计算结果,则需要调用cuda.synchronize()来进行同步。
from numba import cuda
@cuda.jit
def gpu_print():
idxWithinGrid=cuda.threadIdx.x+cuda.blockIdx.x*cuda.blockDim.x
prind("Hello World in thred",idWithinGrid)
def main():
gpu_print[2,4]()
cuda.synchronize()
if _name_=="_main_":
main()在 CUDA 进行编程开发还涉及到一些基本概念。首先是核函数,核函数是在 GPU 上面跑的函数,在写法上,我们一般会在函数上面加 @cuda.jit 装饰符,任务分配的时候我们要做一个执行配置,在这个case里面,我们的执行配置是中括号里面[2,4],2x4 乘起来是 8,它代表的是这个任务会被并发地执行八次。任务计算完之后,一般整体作业任务会是比较复杂的,后续还可能要执行多个步骤。在执行下一步骤的时候,我们需要用到上一步的计算结果,如果上一步计算是在 GPU 场景下进行的,那我们需要用 cuda.synchronize() 进行计算同步。这段代码和一般作业任务组织不同之处在于核函数处理部分,相当于在常规写法上增加一部分,而这部分其实是基于线程次序的。
GPU线程和物理资源分配
谈及线程次序之前,我们先将线程相关的基础概念进行一些讲解。首先, CUDA 核函数定义的运算都是放在单独线程的,多个线程它可以组成一个块(Block),多个块可以组成一个网络(Grid), 单线程是对应一个 CUDA 的。线程在 Core 上面跑,Block 在 SM 上面跑,Grid 则对应着一个任务。

我们接下来将介绍怎么找线程中的序号,为什么要找这个序号呢?是因为 GPU 要发挥它的性能,而它最大的性能优势在于多核心,所以在 GPU 更适用于并行计算的场景。常规来说我们要对大数据进行切割,然后把它们放在一个一个线程里。当数据处理完成,返回结果的时候,系统默认为乱序返回,所以如果我们不知道线程对应的是哪个序号的话,数据就回不去了。
我们在用 GPU 计算的时候,核心的工作是做数据和线程绑定,那么线程怎么去做绑定呢?首先我们要先会找线程的序号,在 CUDA 中找线程序号是比较容易的,因为 CUDA 已经内置了我们所需要用的参数了。

· blockDim.x:表示block的大小是4,即每个block有4个thread;
· threadIdx.x:是一个从0到blockDim.x - 1(4-1=3)的索引下标,记录这是第几个thread;
· gridDim.x:表示grid的大小是2,即每个grid有2个block;
· blockIdx.x:是一个从0到gridDim.x - 1(2-1=1)的索引下标,记录这是第几个block
最重要参数是上面的这4个。 blockDim.x 是表示已设置的 block大小; threadIdx.x 是我们的线程的序号,它表示的是单个 block 线程序号,从 0 到 blockDim.x-1;下面这个 gridDim.x 表示,作业任务分配多少个 block;blockIdx.x 是表示的是在 grid 里 block 的次序。比如说,这个绿框表示的线程是在第一个 block 里面的第二个次序。

· 某个thread在整个grid中的位置编号为:threadIdx.x + blockIdx.x * blockDim.x
有了4个参数之后,接下来计算就很简单了。比如,我们要计算 2 号序线程,实际上首先我们把确定 blockDim 是在第几个 block,再加上它在这个 block 里的次序,就可以获得。
执行配置 [gridDim, blockDim]一般遵循的配置规则:
· block运行在SM上,不同硬件架构(Turing、Volta、Pascal…)的CUDA核心数不同,一般需要根据当前硬件来设置block的大小blockDim。一个block中的thread数最好是32、128、256的倍数。注意,限于当前硬件的设计,block大小不能超过1024。
· grid的大小gridDim,即一个grid中block的个数可以由总线程数N除以blockDim得到,并向上取整。
· block和grid的大小可以设置为二维甚至三维。
如何设计执行配置
了解到核函数如何通过线程次序进行绑定后,接下来我们涉及到的是执行配置的操作问题。执行配置分两部分,(1)gridDim(2)blockDim。blockDim 表示任务要怎么分,一个 block 里面要包含多少线程;gridDim表示作业任务要分配多少 block,在整个执行过程中,我们很多调配工作是依赖于经验的,具有一定的实验性质。这主要是因为我们使用的 GPU 的硬件架构设计不一样,很多时候要参考技术表。技术表介绍了计算任务和其限制,以及最终这些内容在物理架构上是怎样实现的。如果我们需要极致优化计算性能,一般来说要根据计算卡本身的属性去做相应场景的适配,而且很多时候我们是需要通过调试来完成优化的。
我们说到的 blockDim、gridDim ,它最多可以写成三维。相较于 gridDim,这个 blockDim 尤其需要我们注意,它虽然可以写成三维 x、y、z,但是它是一个 block 最多只能包含 1024 个线程。所以不管 x、y 这里写了多少,相乘得到的最终数值不能超过1024。
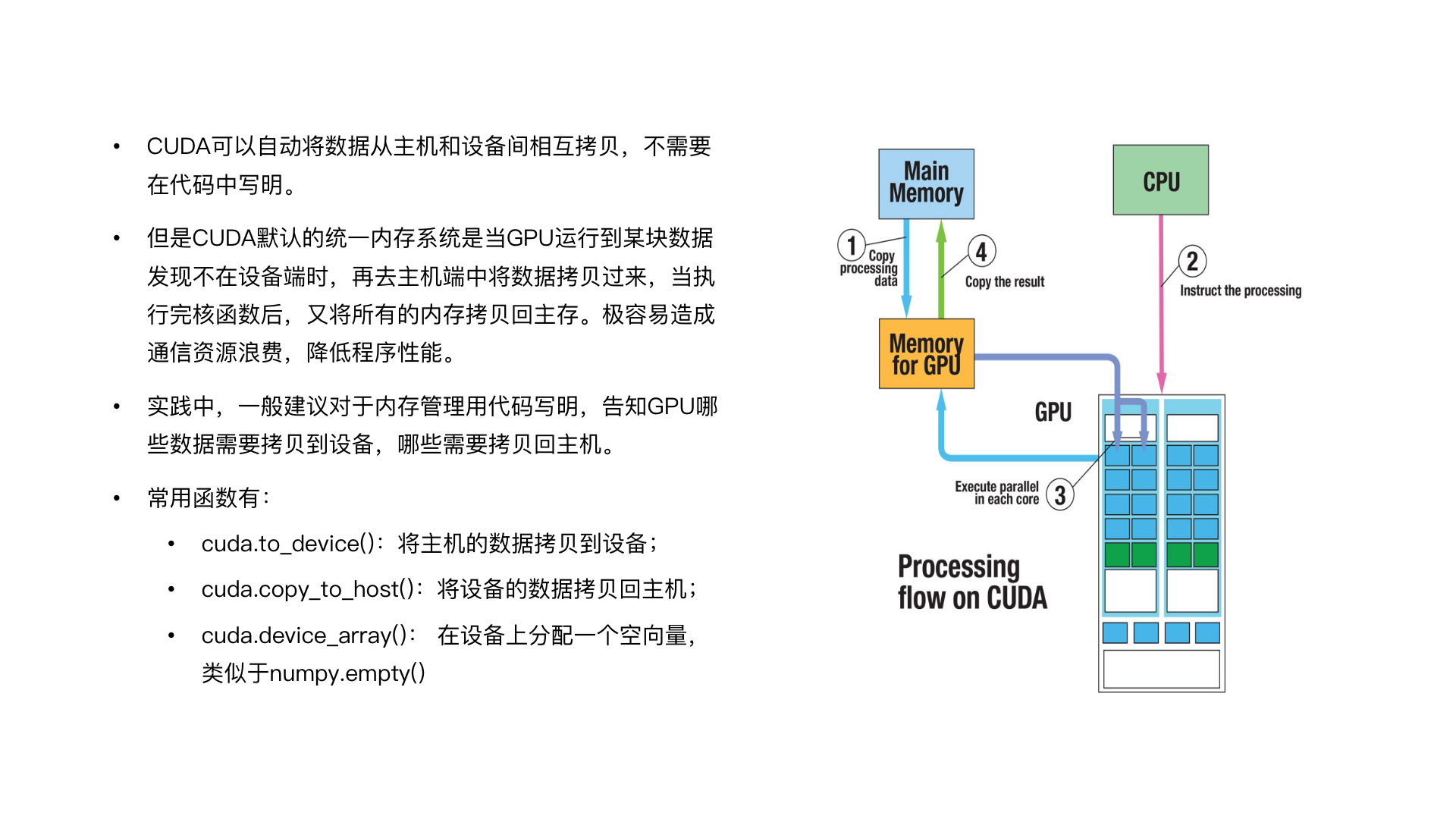
我们再来看一下 CUDA 对于数据在 bus 层的调取机制是怎样的。CUDA 在调取机制上进行了自动化处理,做计算的时候,如果我们所调用的数据没有在内存上面,调取机制启动后,系统会自动在内存上拉取进行计算。在数据计算量较大的情况下,我们需要对数据进行切分再进行并行计算,如果计算步骤较多,自动机制容易造成通信资源的浪费。因为下一步的计算也是在 GPU 上进行的,但是如果系统进行自动拉取,它会把数据就直接又拷贝回内存,进行下一步计算的时候,它又要从内存里面去拉取过来,这时候整体的性能会受到很大影响。
如果我们处理的是大数据类型,进行大型层计算的话,我们在写脚本的时候应该先把数据进行分配,用脚本的形式直接写好。明写出来的需要用到一些函数。这边最常用的话是 cuda.to_device() ,它代表的是把主机上面的数据拷贝到设备;另外一个常用的函数是 cuda.copy_to_host(),它代表的是计算最终完成了,把结果拷贝回内存里。由于最终的计算结果整体的数据维度可能也比较大,那么我们事先应该先开辟这个空间,可以用 cuda.device_array() 和 numpy.empty() 等功能去访问。基本上 CUDA 编程就会用到以上这些内容。
from numba import cuda
import numpy as np
import math
from time import time
@cuda.jit
def gpu_add(a, b, result, n):
idx = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
if idx < n :
result[idx] = a[idx] + b[idx]
def main():
n = 20000
x = np.arange(n).astype(np.int32)
y = 2 * x
# 拷贝数据到设备端
x_device = cuda.to_device(x)
y_device = cuda.to_device(y)
# 在显卡设备上初始化一块用于存放GPU计算结果的空间
gpu_result = cuda.device_array(n)
cpu_result = np.empty(n)
threads_per_block = 1024
blocks_per_grid = math.ceil(n / threads_per_block)
start = time()
gpu_add[blocks_per_grid, threads_per_block](x_device, y_device, gpu_result, n)
cuda.synchronize()
print("gpu vector add time " + str(time() - start))
start = time()
cpu_result = np.add(x, y)
print("cpu vector add time " + str(time() - start))
if (np.array_equal(cpu_result, gpu_result.copy_to_host())):
print("result correct!")
if __name__ == "__main__":
main()这是一个简单的 demo 程序,用 GPU 做加法,加法的函数很简单。首先我们先找到线程序号,这一点是按照次序把数据计算填到每个结果的向量中,在进行资源配置的时候,block 分配有 1024 的限制。常规来说 gridDim 任务中每一个 grid 要分配多少 block,是通过整体计算量去除以每一个 block 里面的线程数量得到的,即除以1024,再向上取整去算,很多情况下会产生冗余的线程。在设计核函数的时候我们会加一个判定,当线程次序已经运行到我们不需要冗余线程的时候,就强制解除。
我们现在基本上已经掌握基本 CUDA 编程的写法,现在我们对刚才求相关性的作业做了重启,我们把它迁移到 GPU 环境再尝试运行,现在可以看到显存利用的情况,虽然计算中有波动,但是峰值还没有超过 6 个G,任务花费的时间已经从刚才的 45 秒优化到了 5.5 秒。很多数据科学相关作业场景,都是适合放在 GPU 上去做计算的。虽然迁移的工作量并不小,但是我们获得的性能提升非常大。
CUDA编程特性-多流
已经迁移到 GPU 上计算的这个任务,有没有可能再做进一步优化呢?其实它的优化空间还非常大。我们刚才只是交代了 CUDA 编程里面的一些基础写法,其实 CUDA 里面还有很多优化点,这都是来自于 CUDA 自身一系列编程特性。今天我先介绍多流的特性。
首先说一下流的概念,它指的是 CUDA 将放入队列顺序执行的一系列操作。多流在 CPU 中也经常会用的,在 GPU 上的执行的情况也差不多。“多流”指的是把一个大任务拆分开,放到多个流中,每次只对一部分数据进行拷贝、计算和回写,并把这个流程做成流水线,大任务的计算和数据拷贝进行并发执行,从而获得性能提升。
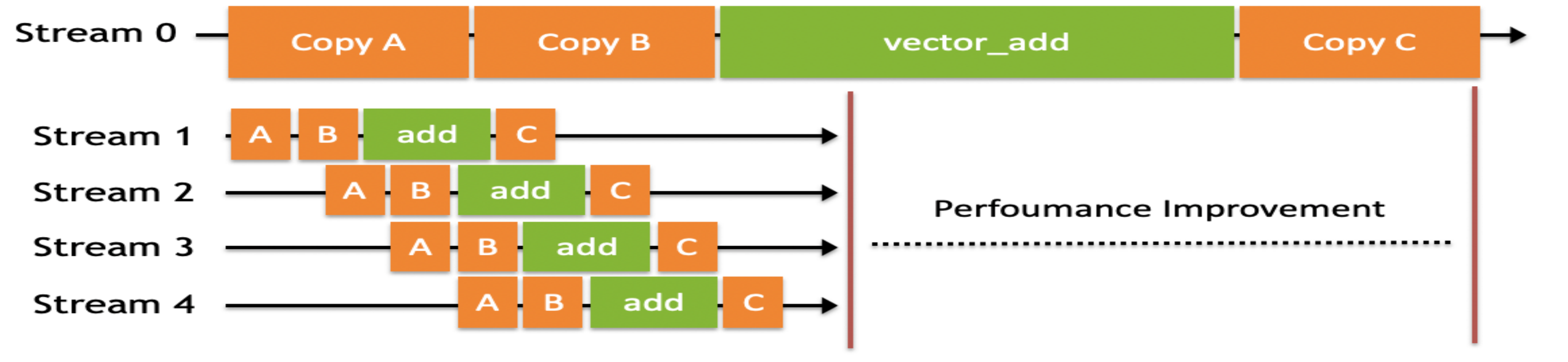
stream 0 就是默认的流,刚才已经执行那一份 CUDA 脚本是用默认的流去计算的。我们把所有需要计算的整份数据先统一拷贝到显存上面,进行计算后再统一地拷贝回来。如果我们换成多流的方式去处理,针对特别大的数据先拆分再放在不同流并发去执行。相较于默认的流,拆分所需要拷贝时间花费的时间,远小于多流写法中节省的计算时间,所以整体这个计算性能是有提升的。
· 使用多流时先定义流:stream = numba.cuda.stream()
· CUDA的数据拷贝以及核函数都有专门的stream参数来接收流,以告知该操作放入哪个流中执行
numba.cuda.to_device(obj, stream=0, copy=True, to=None)
numba.cuda.copy_to_host(self, ary=None, stream=0)
· 核函数调用的地方除了要写清执行配置,还要加一项stream参数
kernel[blocks_per_grid, threads_per_block, stream=0]
以上是使用多流会用到的基础的函数,包括怎么样去定义流。我们用的是 cuda.stream 去申请一个流。在下面不管是数据的迁移 to_device,to_host,还是具体资源配置放到核函数里面,我们只需要能把序号填进去,就能够实现计算。
from numba import cuda
import numpy as np
import math
from time import time
@cuda.jit
def gpu_add(a, b, result, n):
idx = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
if idx < n :
result[idx] = a[idx] + b[idx]
def main():
n = 20000
x = np.arange(n).astype(np.int32)
y = 2 * x
start = time()
x_device = cuda.to_device(x)
y_device = cuda.to_device(y)
out_device = cuda.device_array(n)
threads_per_block = 1024
blocks_per_grid = math.ceil(n / threads_per_block)
# 使用默认流
gpu_add[blocks_per_grid, threads_per_block](x_device, y_device, out_device, n)
gpu_result = out_device.copy_to_host()
cuda.synchronize()
print("gpu vector add time " + str(time() - start))
start = time()
# 使用5个stream
number_of_streams = 5
# 每个stream处理的数据量为原来的 1/5
# 符号//得到一个整数结果
segment_size = n // number_of_streams
# 创建5个cuda stream
stream_list = list()
for i in range (0, number_of_streams):
stream = cuda.stream()
stream_list.append(stream)
threads_per_block = 1024
# 每个stream的处理的数据变为原来的1/5
blocks_per_grid = math.ceil(segment_size / threads_per_block)
streams_out_device = cuda.device_array(segment_size)
streams_gpu_result = np.empty(n)
# 启动多个stream
for i in range(0, number_of_streams):
# 传入不同的参数,让函数在不同的流执行
x_i_device = cuda.to_device(x[i * segment_size : (i + 1) * segment_size], stream=stream_list[i])
y_i_device = cuda.to_device(y[i * segment_size : (i + 1) * segment_size], stream=stream_list[i])
gpu_add[blocks_per_grid, threads_per_block, stream_list[i]](
x_i_device,
y_i_device,
streams_out_device,
segment_size)
streams_gpu_result[i * segment_size : (i + 1) * segment_size] = streams_out_device.copy_to_host(stream=stream_list[i])
cuda.synchronize()
print("gpu streams vector add time " + str(time() - start))
if __name__ == "__main__":
main()我们回到刚才的 demo 代码。我们即使将其改成多流,核函数也是无需更改的,我们只需要把数据迁移的部分和资源分配的部分改成多流,以上的代码中就包含了多流的写发。首先我们会生成 5 个流,这部分数据做了切分,在迁移的时候我们在函数里把序号填进去,核函数保持一致,这个任务就调配成了多流的模式。
这个任务改成多流后的运行性能是怎么样的?我们可以看到显存的调用波动的范围还是比较大的,但是同样的代码,用默认的流执行最终花费 5.5 秒,用多流去跑只需要 3 点多秒的时间就可以跑完,从百分比上来看,还是有较大的性能提升的,我们的案例计算规模比较小,如果是大规模计算,这样比例的效率提升则会更为可观。
对于个人用户来说的话,平时如果处于学习或爱好去跑一些作业任务,为此单独去买一个显卡是不太经济的。如果我们希望测试不同种类的 GPU 架构的话,就更不划算了。GPU 下面有很多 Python 生态下面的包,都是最近进行开发和维护的,除非我们非常熟悉它们的特性,否则作环境配置的时候,会碰到一些不知名的问题。环境配置其实是比较麻烦,尤其有一些包在互相之间调用的时候,所需要调的 CUDA 层版本可能不大匹配。在这种情况下,矩池云MATPool应运而生,大家的数据、计算脚本等等都可以放在网盘,调用数据、调用 GPU 资源等也都是开箱即用的模式。我们可以在一个已经布置好环境的场景中调用 GPU,我们的网盘里面已经存有脚本和数据,也就是说一旦计算任务完成了,我们可以直接把物理资源释放,这样我们也就相当于拥有了随身携带的 GPU 计算资源。
现场视频
本文包含的内容,均整理自Matpool矩池云在PyCon大会-Python Meetup杭州站上的演讲,现场视频如下